The day deep learning took computer vision by storm
Sep 1, 2014
The first time I heard about "deep learning" was a couple of days before the 2012 European Conference on Computer Vision (ECCV 2012) took place in Firenze, Italy. At the time I was working as a computer vision scientist with interest in image detection and classification. In particular, I was especially interested in the PASCAL and ImageNet image classification challenges that take place every year.
Shortly before I boarded my plane to Italy, word had come out that one of the contestants in the ImageNet challenge had results that vastly outperformed all others. This was unusual for two reasons. First, it's very rare that the winner of one of the challenges outperforms the second, or even the third peformer, by more than a couple percentage points. There isn't much secrecy between the teams, so they all (kinda) pick their ideas from a common pool of efficient, published methods. Winning teams are usually the ones that have applied one or more interesting tweaks to an existing method. And that's the second reason why the result was surprising: that year, the winning team of ImageNet had used neural networks for image classification. Now, in computer vision, the last time someone had produced interesting results involving neural networks was in the 1990s -- prehistory, in other words.
The ECCV workshop during which contestants presented their methods and winners received their awards was taking place on the very last day of the conference, and I remember it quite vividly. First, the results for the PASCAL challenge were presented: nothing too surprising there. Progressively the small, half-empty room starts to fill up. After a couple hours, when it's finally time to present the ImageNet results, the room is packed: all seats are occupied and there are people sitting on the floor or standing as far as the doorway.
Ass kicking time
Finally, it was time for the "neural network thing" presentation. Alex Krizhevsky gets on stage. So the whole room (and corridor) starts listening to this pale, thin, glass-wearing, extremely nerdy PhD student who speaks in very precise and factual terms. And this guy proceeds to blowing our minds and kicking our collective asses. This is what it looked like.
We need to clarify something: the ImageNet challenge is probably the most difficult computer vision task for which there exists a publicly available dataset: it's a massive dataset of 1.2 million training images divided in a thousand classes. If you want to participate, your classifier will have to be able to distinguish Australian Terrier from Yorkshire Terrier -- among other things.
Believe me, it's pretty fucking hard.
So this Alex guy is on stage and delivers his presentation. Quantitatively speaking, the results outperform the second best method by 40 percentage points.
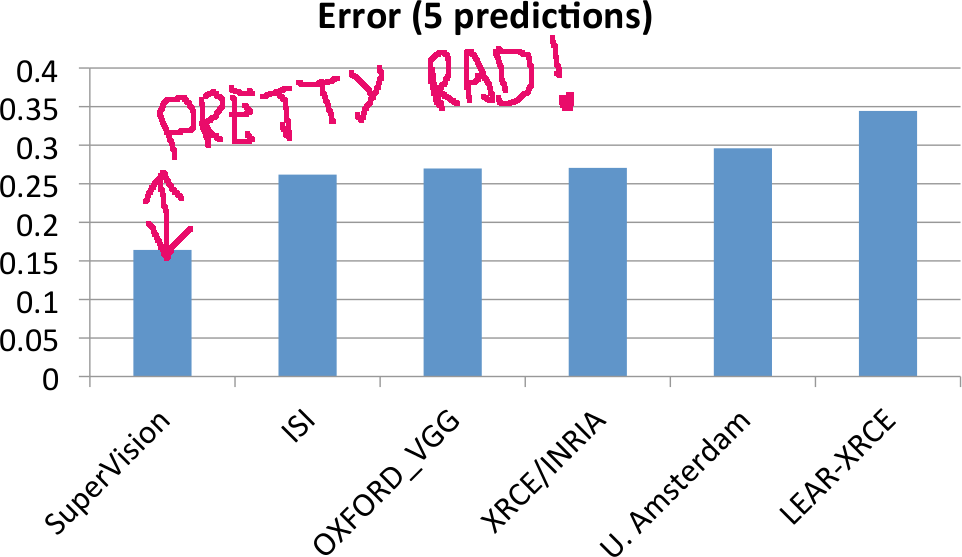
That's big. Huge, actually. Scientists witness such an improvement an average of once per lifetime. This sort of performance increase is not supposed to occur in mature research fields. And the visual results are stunning, too (look at the last slides).
Krizhevsky's and Hinton's approach is fully described in their now-famous NIPS 2012 paper.The science behind the proposed solution seems pretty straightforward, but the genius lies in the implementation of the deep neural network: in the presentation, Alex describes at great length his GPU implementation which is the actual breakthough behind the great results he obtained -- this and the sheer amount of labelled, training data made available in ImageNet. In other words, the labelled training data provided in previous public computer vision datasets were not large enough for deep neural networks that have a very large number of parameters. By the way, in his presentation Alex made it abundantly clear that, despite the size of ImageNet, his deep neural network was overfitting the data. I find this exhilarating.
"Where did I put this old neural networks book again?"
So Alex ends his presentation, the audience is stunned and there is some clapping. Many are thinking: "Have we worked all this time for nothing? Should we throw away most computer vision papers from the past decade?" It's time for the traditional question session. Pretty rapidly, the questions acquire an aggressive undertone:
How would your approach work on a more realistic, difficult dataset?
What do your results say about the quality of the ImageNet dataset?
The organisers of the ImageNet challenge are suddenly under a fire of criticisms from some very well respected figures of the computer vision community. The reasoning was that if such a simple method works when so many brilliant people have tried such complex ideas, then the dataset on which the experiment was conducted was flawed. As the manager of the ImageNet challenge, Li Fei Fei is taking most of the heat. Yann LeCun, a long-time proponent of neural networks is there too and most questions are now directed to him. I remember Li Fei Fei her asking him:
How is the method you just described conceptually different from your 1988 paper?
To which Yann answers:
It's exactly the same method!
I got really depressed by that.
Aftermath
Of course, we now know that the success of deep neural networks on the ImageNet was not an isolated, singular event. Two years later, deep convolutional neural networks (CNN) have outperformed more traditional methods in most computer vision problems. It's revolution. Yann LeCun and Geoffrey Hinton have been acqui-hired by Facebook and Google, respectively. And the ImageNet challenge is doing just fine, thank you.
I consider it a privilege to have attended this particular presentation; I could have learned about the science behind CNN just by reading papers, but what I had not foreseen was the incredible resistance that the computer vision community opposed to CNN, in the beginnings. Scientists are the makers of change, yet they could not accept the wave of change that was crashing on them. Hey, they are humans too, right? right?